arviz_plots.plot_ppc_pava_residuals#
- arviz_plots.plot_ppc_pava_residuals(dt, x_var, data_type='binary', ci_prob=None, var_names=None, filter_vars=None, group='posterior_predictive', coords=None, sample_dims=None, plot_collection=None, backend=None, labeller=None, aes_by_visuals=None, visuals=None, **pc_kwargs)[source]#
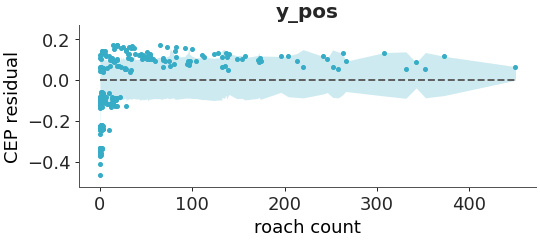
PAV-adjusted calibration residual plot.
Uses the pool adjacent violators (PAV) algorithm for isotonic regression and computes residuals as the difference between the calibrated event probabilities (CEP) and the predicted probabilities. A horizontal line at zero corresponds to perfect calibration. Details are discussed in [1] and [2].
- Parameters:
- dt
xarray.DataTree Input data
- x_vararray_like,
series,xarray.DataArray, orstr Variable to use for x-axis. If a string is given, it should be the name of a variable in the constant_data group.
- data_type
str Defaults to “binary”. Other options are “categorical” and “ordinal”. If “categorical”, the plot will show the “one-vs-others” calibration and generate one plot per category. If “ordinal”, the plot will display cumulative conditional event probabilities and generate (number of categories - 1) plots.
- ci_prob
float, optional Probability for the credible interval. Defaults to
rcParams["stats.ci_prob"].- var_names
strorlistofstr, optional One or more variables to be plotted. Currently only one variable is supported. Prefix the variables by ~ when you want to exclude them from the plot.
- filter_vars{
None, “like”, “regex”}, optional, default=None If None (default), interpret var_names as the real variables names. If “like”, interpret var_names as substrings of the real variables names. If “regex”, interpret var_names as regular expressions on the real variables names.
- group
str, optional The group from which to get the unique values. Defaults to “posterior_predictive”. It could also be “prior_predictive”. Notice that this plots always use the “observed_data” so use with extra care if you are using “prior_predictive”.
- coords
dict, optional Coordinates to plot. CURRENTLY NOT IMPLEMENTED
- sample_dims
stror sequence of hashable, optional Dimensions to reduce unless mapped to an aesthetic. Defaults to
rcParams["data.sample_dims"]- plot_collection
PlotCollection, optional - backend{“matplotlib”, “bokeh”, “plotly”}, optional
- labeller
labeller, optional - aes_by_visualsmapping of {
strsequence ofstr}, optional Mapping of visuals to aesthetics that should use their mapping in
plot_collectionwhen plotted. Valid keys are the same as forvisuals.- visualsmapping of {
strmapping or bool}, optional Valid keys are:
markers -> passed to
scatter_xyreference_line -> passed to
line_xcredible_interval -> passed to
fill_between_yxlabel -> passed to
labelled_xylabel -> passed to
labelled_ytitle -> passed to
labelled_title
markers defaults to True for residual plots. Pass False to disable markers.
- **pc_kwargs
Passed to
arviz_plots.PlotCollection.grid
- dt
- Returns:
References
[1]Säilynoja et al. Recommendations for visual predictive checks in Bayesian workflow. (2025) arXiv preprint https://arxiv.org/abs/2503.01509
[2]Dimitriadis et al Stable reliability diagrams for probabilistic classifiers. PNAS, 118(8) (2021). https://doi.org/10.1073/pnas.2016191118
Examples
Plot the PAVA residual plot for the zeros and non-zeros in a negative bimomial model of the roaches dataset.
>>> from arviz_plots import plot_ppc_pava_residuals, style >>> style.use("arviz-variat") >>> from arviz_base import load_arviz_data >>> dt = load_arviz_data('roaches_nb') >>> plot_ppc_pava_residuals(dt, >>> var_names="y_pos", >>> x_var="roach count")